在现代 Web 开发中,数据上传的需求日益增多,特别是在处理大规模数据时,传统的大文件上传方式已经难以满足高效、稳定的需求。本文将结合实际项目,详细介绍如何在 Vue 3 和 TypeScript 环境中实现大文件分片上传,并进行性能优化。
1. 项目技术栈
项目采用了以下技术栈:
-
前端:Vue 3 + TypeScript + Vue Router + Pinia + Element Plus + Axios + Normalize.css
- 使用 Vue 3 Composition API 和 Pinia 管理全局状态,确保代码结构清晰,状态管理便捷。
- TypeScript 提供了强大的类型检查机制,减少了运行时错误,增强了代码的可维护性。
- Vue Router 4 负责管理应用路由,Element Plus 提供了丰富的 UI 组件,而 Axios 则用于处理网络请求。
- 使用 Vite 作为开发和构建工具,提升了开发效率。
-
后端:Node.js + Koa.js + TypeScript + Koa Router
- 通过 Koa.js 与 TypeScript 的结合,使用 Koa Router 加强服务端路由管理,优化开发体验,并集成了全局异常拦截与日志功能。
2. 前端设计与实现
前端的核心在于如何高效处理大文件的上传。传统的单一文件上传方式容易因网络波动导致上传失败,而分片上传则能有效避免此类问题。以下是分片上传的主要实现步骤:
-
文件切片: 使用
Blob.prototype.slice方法,将大文件切分为多个 10MB 的小块。每个切片都具有唯一的标识,确保了上传的完整性和正确性。文件秒传,即在服务端已经存在了上传的资源,所以当用户再次上传时会直接提示上传成功。文件秒传需要依赖上一步生成的 hash,即在上传前,先计算出文件 hash,并把 hash 发送给服务端进行验证,由于 hash 的唯一性,所以一旦服务端能找到 hash 相同的文件,则直接返回上传成功的信息即可。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
const CHUNK_SIZE = 10 * 1024 * 1024; // 文件上传服务器 async function submitUpload() { if (!file.value) { ElMessage.error('Oops, 请您选择文件后再操作~~.'); return; } // 将文件切片 const chunks: IFileSlice[] = []; let cur = 0; while (cur < file.value.raw!.size) { const slice = file.value.raw!.slice(cur, cur + CHUNK_SIZE); chunks.push({ chunk: slice, size: slice.size, }); cur += CHUNK_SIZE; } // 计算hash hash.value = await calculateHash(chunks); fileChunks.value = chunks.map((item, index) => ({ ...item, hash: `${hash.value}-${index}`, progress: 0, })); // 校验文件是否已存在 await fileStore.verifyFileAction({ filename: file.value.name, fileHash: hash.value, }); const { exists } = storeToRefs(fileStore); if (!exists.value) { await uploadChunks({ chunks, hash: hash.value, totalChunksCount: fileChunks.value.length, uploadedChunks: 0, }); } else { ElMessage.success('秒传: 文件上传成功'); } }
-
并发上传与调度: 实现了一个并发控制的
Scheduler,限制同时上传的切片数为 3,避免因过多并发请求导致的系统卡顿或崩溃。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106
// scheduler.ts export class Scheduler { private queue: (() => Promise<void>)[] = []; private maxCount: number; private runCounts = 0; constructor(limit: number) { this.maxCount = limit; } add(promiseCreator: () => Promise<void>) { this.queue.push(promiseCreator); this.run(); } private run() { if (this.runCounts >= this.maxCount || this.queue.length === 0) { return; } this.runCounts++; const task = this.queue.shift()!; task().finally(() => { this.runCounts--; this.run(); }); } } // UploadFile.vue // 切片上传 limit-限制并发数 async function uploadChunks({ chunks, hash, totalChunksCount, uploadedChunks, limit = 3, }: IUploadChunkParams) { const scheduler = new Scheduler(limit); const totalChunks = chunks.length; let uploadedChunksCount = 0; for (let i = 0; i < chunks.length; i++) { const { chunk } = chunks[i]; let h = ''; if (chunks[i].hash) { h = chunks[i].hash as string; } else { h = `${hash}-${chunks.indexOf(chunks[i])}`; } const params = { chunk, hash: h, fileHash: hash, filename: file.value?.name as string, size: file.value?.size, } as IUploadChunkControllerParams; scheduler.add(() => { const controller = new AbortController(); controllersMap.set(i, controller); const { signal } = controller; console.log(`开始上传切片 ${i}`); if (!upload.value) { return Promise.reject('上传暂停'); } return fileStore .uploadChunkAction(params, onTick, i, signal) .then(() => { console.log(`完成切片的上传 ${i}`); uploadedChunksCount++; // 判断所有切片都已上传完成后,调用mergeRequest方法 if (uploadedChunksCount === totalChunks) { mergeRequest(); } }) .catch((error) => { if (error.name === 'AbortError') { console.log('上传被取消'); } else { throw error; } }) .finally(() => { // 完成后将控制器从map中移除 controllersMap.delete(i); }); }); } function onTick(index: number, percent: number) { chunks[index].percentage = percent; const newChunksProgress = chunks.reduce( (sum, chunk) => sum + (chunk.percentage || 0), 0 ); const totalProgress = (newChunksProgress + uploadedChunks * 100) / totalChunksCount; file.value!.percentage = Number(totalProgress.toFixed(2)); } }
-
Web Worker 计算文件 Hash: 为了避免阻塞主线程,使用 Web Worker 计算每个切片的 Hash 值,用于服务器端的文件校验。这一步确保了文件的唯一性,避免了重复上传。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58
// hash.ts import SparkMD5 from 'spark-md5'; const ctx: Worker = self as any; ctx.onmessage = (e) => { // 接收主线程的通知 const { chunks } = e.data; const blob = new Blob(chunks); const spark = new SparkMD5.ArrayBuffer(); const reader = new FileReader(); reader.onload = (e) => { spark.append(e.target?.result as ArrayBuffer); const hash = spark.end(); ctx.postMessage({ progress: 100, hash, }); }; reader.onerror = (e: any) => { ctx.postMessage({ error: e.message, }); }; reader.onprogress = (e) => { if (e.lengthComputable) { const progress = (e.loaded / e.total) * 100; ctx.postMessage({ progress, }); } }; // 读取Blob对象的内容 reader.readAsArrayBuffer(blob); }; ctx.onerror = (e) => { ctx.postMessage({ error: e.message, }); }; // UploadFile.vue // 使用Web Worker进行hash计算的函数 function calculateHash(fileChunks: IFileSlice[]): Promise<string> { return new Promise<string>((resolve, reject) => { const worker = new HashWorker(); worker.postMessage({ chunks: fileChunks }); worker.onmessage = (e) => { const { hash } = e.data; if (hash) { resolve(hash); } }; worker.onerror = (event) => { worker.terminate(); reject(event.error); }; }); }
-
断点续传与秒传: 通过前端判断服务器上已有的文件切片,支持断点续传和秒传功能。用户不需要重新上传整个文件,而只需上传未完成的部分,极大地提升了上传效率。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
// 上传暂停和继续 async function handlePause() { upload.value = !upload.value; if (upload.value) { // 校验文件是否已存在 if (!file.value?.name) { return; } await fileStore.verifyFileAction({ filename: file.value.name, fileHash: hash.value, }); const { exists, existsList } = storeToRefs(fileStore); const newChunks = fileChunks.value.filter((item) => { return !existsList.value.includes(item.hash || ''); }); console.log('newChunks', newChunks); if (!exists.value) { await uploadChunks({ chunks: newChunks, hash: hash.value, totalChunksCount: fileChunks.value.length, uploadedChunks: fileChunks.value.length - newChunks.length, }); } else { ElMessage.success('秒传: 文件上传成功'); } } else { console.log('暂停上传'); abortAll(); } }
-
用户体验优化: 为了提升用户体验,添加了拖拽上传、上传进度显示、文件暂停与续传等功能。这些优化不仅增强了系统的健壮性,还使用户在处理大文件时体验更为流畅。
3. 后端实现与整合
后端使用 Koa.js 构建,核心在于如何高效接收并合并前端上传的文件切片。具体步骤如下:
-
文件接收与存储: 通过 Koa Router 定义的 API 端点接收前端上传的切片,使用
ctx.request.files获取上传的文件,并通过ctx.request.body获取其他字段信息。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112
// verify.ts 校验文件是否存储 import { type Context } from 'koa'; import { type IUploadedFile, type GetFileControllerResponse, type IVefiryFileControllerParams, type VefiryFileControllerResponse, } from '../utils/types'; import fileSizesStore from '../utils/fileSizesStore'; import { HttpError, HttpStatus } from '../utils/http-error'; import { UPLOAD_DIR, extractExt, getChunkDir, getUploadedList, isValidString, } from '../utils'; import { IMiddleware } from 'koa-router'; import { Controller } from '../controller'; import path from 'path'; import fse from 'fs-extra'; const fnVerify: IMiddleware = async ( ctx: Context, next: () => Promise<void> ) => { const { filename, fileHash } = ctx.request .body as IVefiryFileControllerParams; if (!isValidString(fileHash)) { throw new HttpError(HttpStatus.PARAMS_ERROR, 'fileHash 不能为空'); } if (!isValidString(filename)) { throw new HttpError(HttpStatus.PARAMS_ERROR, 'filename 不能为空'); } const ext = extractExt(filename!); const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${ext}`); let isExist = false; let existsList: string[] = []; if (fse.existsSync(filePath)) { isExist = true; } else { existsList = await getUploadedList(fileHash!); } ctx.body = { code: 0, data: { exists: isExist, existsList: existsList }, } as VefiryFileControllerResponse; await next(); }; // 获取所有已上传文件的接口 const fnGetFile: IMiddleware = async ( ctx: Context, next: () => Promise<void> ): Promise<void> => { const files = await fse.readdir(UPLOAD_DIR).catch(() => []); const fileListPromises = files .filter((file) => !file.endsWith('.json')) .map(async (file) => { const filePath = path.resolve(UPLOAD_DIR, file); const stat = fse.statSync(filePath); const ext = extractExt(file); let fileHash = ''; let size = stat.size; if (file.includes('chunkDir_')) { fileHash = file.slice('chunkDir_'.length); const chunkDir = getChunkDir(fileHash); const chunks = await fse.readdir(chunkDir); let totalSize = 0; for (const chunk of chunks) { const chunkPath = path.resolve(chunkDir, chunk); const stat = await fse.stat(chunkPath); totalSize += stat.size; } size = totalSize; } else { fileHash = file.slice(0, file.length - ext.length); } const total = await fileSizesStore.getFileSize(fileHash); return { name: file, uploadedSize: size, totalSize: total, time: stat.mtime.toISOString(), hash: fileHash, } as IUploadedFile; }); const fileList = await Promise.all(fileListPromises); ctx.body = { code: 0, data: { files: fileList }, } as GetFileControllerResponse; await next(); }; const controllers: Controller[] = [ { method: 'POST', path: '/api/verify', fn: fnVerify, }, { method: 'GET', path: '/api/files', fn: fnGetFile, }, ]; export default controllers;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97
// upload.ts 上传切片 import { IMiddleware } from 'koa-router'; import { UPLOAD_DIR, extractExt, getChunkDir, isValidString, } from '../utils'; import fileSizesStore from '../utils/fileSizesStore'; import { HttpError, HttpStatus } from '../utils/http-error'; import { type IUploadChunkControllerParams, type UploadChunkControllerResponse, } from '../utils/types'; import path from 'path'; import fse from 'fs-extra'; import { Controller } from '../controller'; import { Context } from 'koa'; import koaBody from 'koa-body'; const fnUpload: IMiddleware = async ( ctx: Context, next: () => Promise<void> ) => { const { filename, fileHash, hash, size } = ctx.request .body as IUploadChunkControllerParams; const chunkFile = ctx.request.files?.chunk; if (!chunkFile || Array.isArray(chunkFile)) { throw new Error(`无效的块文件参数`); } const chunk = await fse.readFile(chunkFile.filepath); if (!isValidString(fileHash)) { throw new HttpError(HttpStatus.PARAMS_ERROR, 'fileHash 不能为空: '); } if (isValidString(chunk)) { throw new HttpError(HttpStatus.PARAMS_ERROR, 'chunk 不能为空'); } if (!isValidString(filename)) { throw new HttpError(HttpStatus.PARAMS_ERROR, 'filename 不能为空'); } const params = { filename, fileHash, hash, chunk, size, } as IUploadChunkControllerParams; fileSizesStore.storeFileSize(fileHash, size); const ext = extractExt(params.filename!); const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${ext}`); const chunkDir = getChunkDir(params.fileHash!); const chunkPath = path.resolve(chunkDir, params.hash!); // 切片目录不存在,创建切片目录 if (!(await fse.pathExists(chunkDir))) { await fse.mkdir(chunkDir, { recursive: true }); } // 文件存在直接返回 if (await fse.pathExists(filePath)) { ctx.body = { code: 1, message: 'file exist', data: { hash: fileHash }, } as UploadChunkControllerResponse; return; } // 切片存在直接返回 if (await fse.pathExists(chunkPath)) { ctx.body = { code: 2, message: 'chunk exist', data: { hash: fileHash }, } as UploadChunkControllerResponse; return; } await fse.move(chunkFile.filepath, `${chunkDir}/${hash}`); ctx.body = { code: 0, message: 'received file chunk', data: { hash: params.fileHash }, } as UploadChunkControllerResponse; await next(); }; const controllers: Controller[] = [ { method: 'POST', path: '/api/upload', fn: fnUpload, middleware: [koaBody({ multipart: true })], }, ]; export default controllers;
-
切片合并: 当所有切片上传完成后,后端会根据前端传来的请求对切片进行合并。这里使用了 Node.js 的 Stream 进行并发写入,提高了合并效率,并减少了内存占用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93
// merge.ts import { UPLOAD_DIR, extractExt, getChunkDir, isValidString, } from '../utils'; import { HttpError, HttpStatus } from '../utils/http-error'; import type { IMergeChunksControllerParams, MergeChunksControllerResponse, } from '../utils/types'; import path from 'path'; import fse from 'fs-extra'; import { IMiddleware } from 'koa-router'; import { Controller } from '../controller'; import { Context } from 'koa'; // 写入文件流 const pipeStream = ( filePath: string, writeStream: NodeJS.WritableStream ): Promise<boolean> => { return new Promise((resolve) => { const readStream = fse.createReadStream(filePath); readStream.on('end', () => { fse.unlinkSync(filePath); resolve(true); }); readStream.pipe(writeStream); }); }; const mergeFileChunk = async ( filePath: string, fileHash: string, size: number ) => { const chunkDir = getChunkDir(fileHash); const chunkPaths = await fse.readdir(chunkDir); // 切片排序 chunkPaths.sort((a, b) => { return a.split('-')[1] - b.split('-')[1]; }); // 写入文件 await Promise.all( chunkPaths.map((chunkPath, index) => pipeStream( path.resolve(chunkDir, chunkPath), // 根据 size 在指定位置创建可写流 fse.createWriteStream(filePath, { start: index * size, }) ) ) ); // 合并后删除保存切片的目录 fse.rmdirSync(chunkDir); }; const fnMerge: IMiddleware = async ( ctx: Context, next: () => Promise<void> ) => { const { filename, fileHash, size } = ctx.request .body as IMergeChunksControllerParams; if (!isValidString(fileHash)) { throw new HttpError(HttpStatus.PARAMS_ERROR, 'fileHash 不能为空: '); } if (!isValidString(filename)) { throw new HttpError(HttpStatus.PARAMS_ERROR, 'filename 不能为空'); } const ext = extractExt(filename!); const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${ext}`); await mergeFileChunk(filePath, fileHash!, size!); ctx.body = { code: 0, message: 'file merged success', data: { hash: fileHash }, } as MergeChunksControllerResponse; await next(); }; const controllers: Controller[] = [ { method: 'POST', path: '/api/merge', fn: fnMerge, }, ]; export default controllers;
-
全局异常处理与日志记录: 为了保证系统的稳定性,服务端实现了全局异常处理和日志记录功能,确保在出现问题时能快速定位并修复。
4. 遇到的问题与解决方案
在实现过程中,我们也遇到了一些挑战:
- 代码结构混乱:在初期开发时,大量的代码逻辑被集中在一起,缺乏合理的抽象与封装。我们通过组件化、工具类方法抽取、状态逻辑分离等方式,逐步优化了代码结构。
- 网络请求封装:为了提高代码的可维护性,我们封装了 Axios,并抽离了 API 相关操作。这样一来,未来即使更换网络请求库,也只需修改一个文件即可。
- 并发请求过多:通过实现一个带有并发限制的
Scheduler,我们确保了系统的稳定性,避免了因过多并发请求导致的系统性能问题。
5. 开发流程图
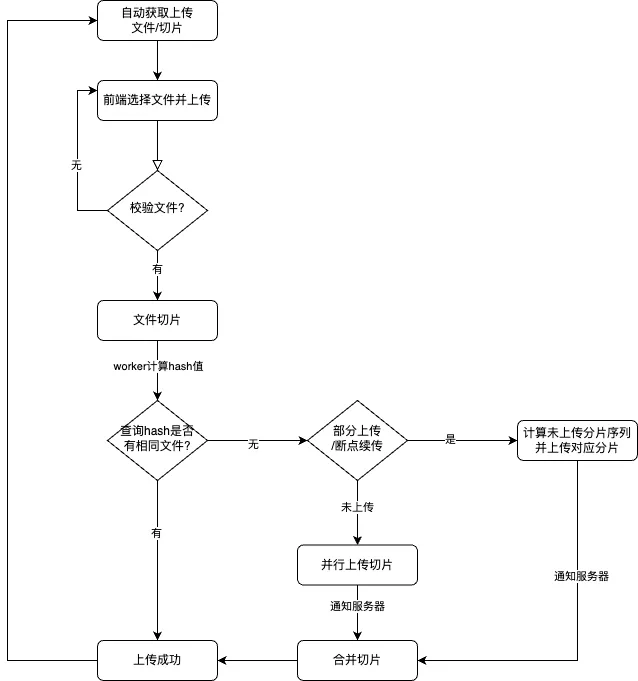
6. 总结
本文介绍了如何在 Vue 3 与 TypeScript 环境中实现大文件的分片上传,并在此基础上进行了多方面的优化。通过这些技术手段,我们不仅提升了系统的性能,还极大地改善了用户体验。随着数据量的不断增长,这种分片上传的方式将会越来越普及,并在未来的开发中发挥重要作用。
这种架构设计为处理大文件上传提供了一个高效、可靠的解决方案,并且具有很强的扩展性和可维护性。希望通过本文的介绍,能为大家在实际项目中解决类似问题提供一些参考和借鉴。